인공지능 중소벤처 제조 플랫폼 포털에서 데이터셋, 가이드북, 실습용 주피터노트북을 모두 다운받을 수 있습니다.
인공지능 중소벤처 제조 플랫폼
데이터셋 소개 원재료를 100℃ 이하의 온도에서 30분 이상 저온살균 및 교반작업 시, 설비운영값 (살균상태, 살균온도, 양품/불량여부)을 수집하여 최종 품질을 예측하기위한 제조 AI분석과정을
kamp-ai.kr
0. 분석 프로세스
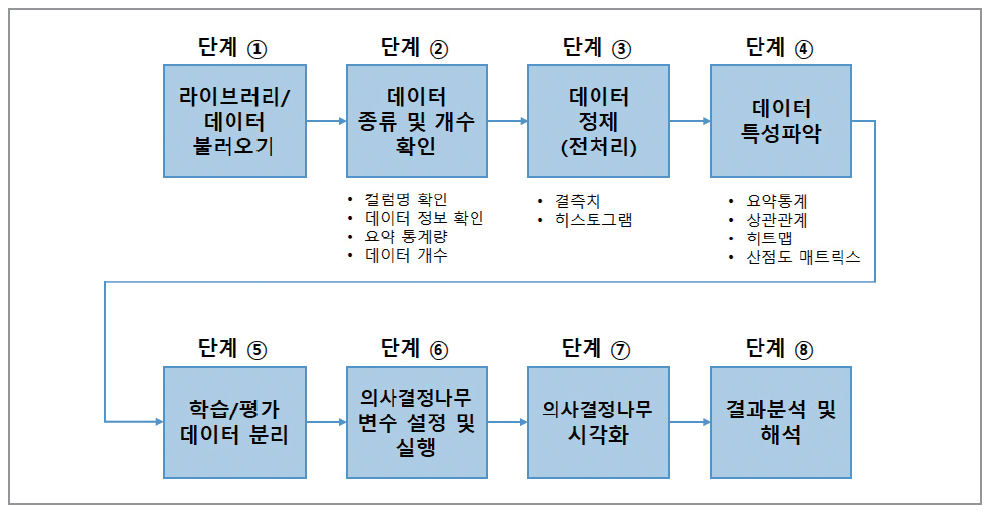
가이드북에는 총 8단계에 걸쳐서 데이터 분석을 진행하고 있습니다.
각 단계를 간략하게 요약하면서 제가 실습했을 때 배운 것 위주로 정리할 예정입니다.
가이드북 정말 잘 나와있어요~! 최고...
* 들어가기 전에
주피터 노트북을 사용할 경우, 패키지를 설치하지 않았으면 라이브러리를 임포트 할 때 에러가 납니다.
!pip install 패키지명
을 입력해서 설치한 이후에 라이브러리 임포트를 하면 에러가 나지 않습니다.
그런데 Graphviz는 환경변수에 Path설정까지 해줘야해서, 이 부분에서 에러가 났었습니다.
다른 블로그 글의 도움을 받아 해결했었는데, 다른 방법은 없을까 하다가 코랩에서는 패키지 설치가 필요하지 않다는 것을 알았습니다.
환경변수 Path 설정이 익숙하지 않은 분들은 코랩에서 돌려보시는 것도 좋을 것 같네요!
1단계. 라이브러리 / 데이터 불러오기
필요한 라이브러리 임포트 하기
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import graphviz
import seaborn as sns
from IPython.display import Image
import pydot
import pydotplus
import pandas as pd
import numpy as np
import os
df = pd.read_csv("pasteurizer.csv") #데이터 업로드
2단계. 데이터 종류 및 개수 확인
df #output화면으로 데이터 확인
df.head(20) #상위 20개 데이터 확인
df.tail() #하위 5개 데이터 확인
df.columns #컬럼명 확인
df.info() #요약통계량 확인
df.describe() #요약통계량 확인
df.shape #데이터 개수 확인
df['INSP'] #특정 컬럼 개수 확인
df['INSP'].value_counts() #특정 컬럼의 값 개수 확인
df.isna().sum() #컬럼별 null 개수 확인
3단계. 데이터 정제
가이드 북에서 사용한 데이터 전처리 방법
- 결측치 제거
- 히스토그램, unique() 함수로 데이터 분포 확인 -> 이상치 제거
df = df.dropna() #null값 있는 행 제거
df.isna().sum() #결측치 제거 결과 확인
plt.hist(df['MIXA_PASTEUR_STATE']) #특정 컬럼의 히스토그램
df['MIXA_PASTEUR_STATE'].unique() #특정 컬럼의 유일한 값 파악
df = df[df.MIXA_PASTEUR_STATE < 2] #특정 컬럼에서 이상치 제거
df.hist(bins=10, figsize=(20, 15)) #모든 컬럼의 히스토그램 그리기
#bins는 막대의 개수를 나타냄
4단계. 데이터 특성 파악
상관표(correlation table), 히트맵, 산점도로 각 컬럼 사이의 상관관계를 확인합니다.
상관표, 히트맵 -> 상관도가 제일 높은 특성을 나타내는 컬럼 확인
(상관계수가 높다고 해서 인과관계가 있다고 볼 순 없지만, 특성들 간의 관계를 쉽게 파악할 수 있다는 장점이 있음)
df.corr() #상관계수 확인
#히트맵
names = ['MIXA_PASTEUR_STATE','MIXB_PASTEUR_STATE','MIXA_PASTEUR_TEMP','MIXB_PASTEUR_TEMP']
cm = np.corrcoef(df[names].values.T)
sns.set(font_scale=0.6)
sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10},
yticklabels=names,xticklabels=names)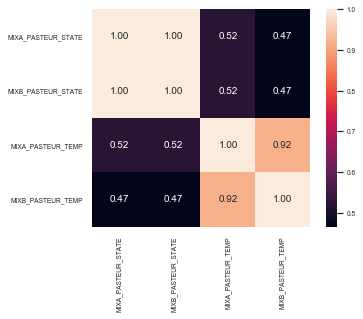
# 산점도 매트릭스
y = df.iloc[:, -1:].values
y = np.where(y == 'OK', 1, 0)
y = y.ravel()
pd.plotting.scatter_matrix(df, c=y, figsize=(15, 15), marker='o',
hist_kwds={'bins':20},s=60,alpha=.8, cmap=plt.cm.Set1)
plt.show()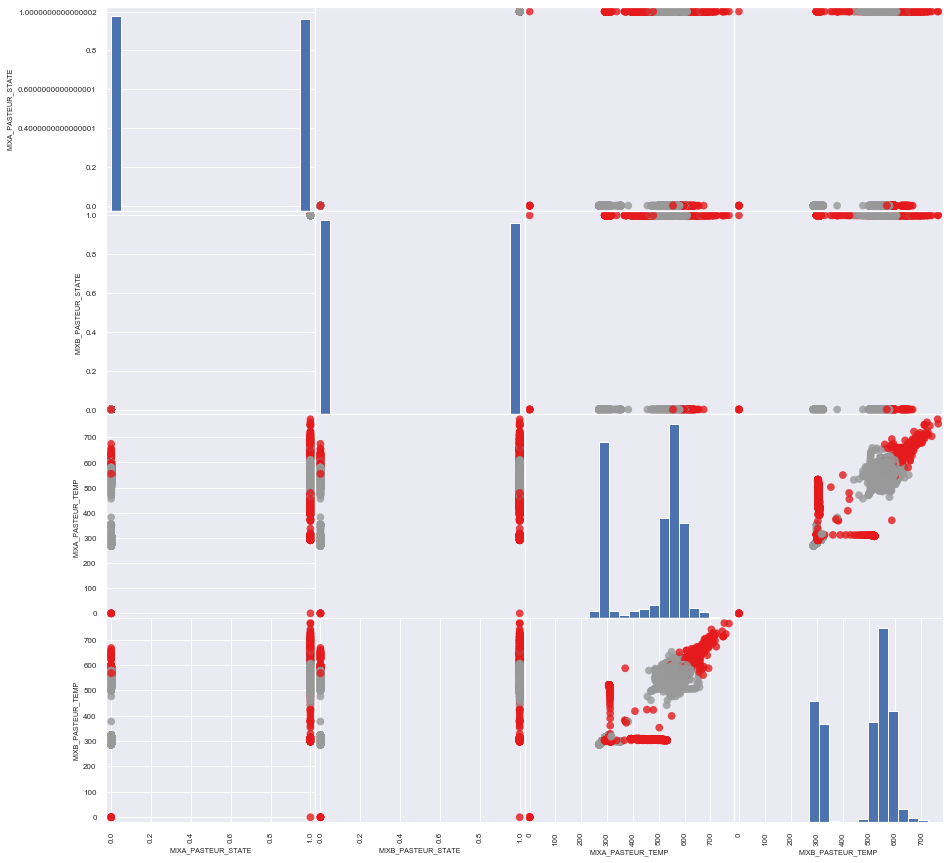
양품은 회색, 불량은 빨간색 점으로 표현.
(4행 3열의 서브그래프) MIXA_PASTEUR_TEMP와 MIXB_PASTEUR_TEMP의 분포를 통해 양품과 불량에 대한 구분이 특정 패턴을 이루고 있다는 것을 짐작해볼 수 있음.
5단계. 학습/평가 데이터 분리
전처리한 9383행의 데이터에서 측정데이터와 레이블을 분리합니다.
# 측정데이터와 레이블(정답)을 분리
X = df.iloc[:, 1:5].values
y = df.iloc[: , -1:].values
y = np.where(y == 'OK', 1, 0)
y = y.ravel() # 레이블을 1차원으로 변경
# print(y.shape)의 결과는 (9383, 1) 입니다
print(X.shape, y.shape) #결과 (9383, 4) (9383,)훈련셋과 테스트셋은 7:3의 비율로 나누어줍니다.
# 훈련셋과 테스트셋 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
6단계. 모델 훈련 - 의사결정나무 실행
DecisionTreeClassifier() 로 의사결정나무 알고리즘 불러오기
max_depth는 가지치기 깊이를 설정하는 함수. 너무 많이 가지를 치면 해석의 용이성이 떨어짐
max_depth는 실제 데이터 분석 과정에서 조정이 가능한 하이퍼파라미터!
.fit() 으로 알고리즘에 데이터를 학습시키기
.predict() 로 훈련된 모델을 테스트하기
dt_clf = DecisionTreeClassifier(max_depth=3)
dt_clf = dt_clf.fit(X_train, y_train)
dt_prediction = dt_clf.predict(X_test)
7단계. 의사결정나무 시각화
시각화 라이브러리에 삽입해야하는 변수를 생성하기
원본 데이터의 변수이름을 추출하고, 타겟변수 이름을 0, 1로 설정
feature_names = df.columns.tolist()
feature_names = feature_names[1:5] #'STD_DT'는 날짜라서 제거, 'INSP'는 타겟이라 제거
target_name = np.array(['0', '1'])
print(target_name) #결과 ['0' '1']
Graphviz로 의사결정나무 시각화하기
dt_dot_data = tree.export_graphviz(dt_clf, feature_names=feature_names, class_names=target_name,
filled=True, rounded = True, special_characters = True)
dt_graph = pydotplus.graph_from_dot_data(dt_dot_data)
Image(dt_graph.create_png())
의사결정나무 시각화 트리리를 해석해보자면, 불량 조건은 두 가지 입니다.
(1) MIXB_PASTEUR_TEMP가 619.5보다 크고, MIXA_PASTEUR_TEMP가 579.5보다 크면 불량(0)
(2) MIXB_PASTEUR_TEMP가 310.5보다 작거나 같고, MIXA_PASTEUR_TEMP가 0.5보다 크면 불량(0)
이 결과를 토대로 MIXB_PASTEUR_TEMP와 MIXA_PASTEUR_TEMP를 관리하면 불량률을 감소시킬 수 있습니다.
또한 온도에 따라 불량이 얼마나 발생할 지 예측도 할 수 있습니다.
*잘못된 결과해석이 있다면, 댓글로 알려주세요
Graphviz가 실행 안된다면 패스를 설정해주시면 됩니다.
# Graphviz 패스설정코드
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/graphviz-2.44.1-win32/Graphviz/bin/'
그래도 안 된다면 (저는 가이드북대로 했다고 생각했는데 안 되길래ㅋㅋ구글검색 후 좋은 블로그를 만났습니다)
블로그 설명대로 해보시길 추천해요. 그래도 안되면ㅋㅋㅋ코랩 ㄱㄱ
Jupyter Notebook + graphviz 사용 설정하기
요즘 python 으로 data 를 이리저리 지지고 볶는 연습을 하고 있는데요그러던 중에 iris 꽃을 분류해보는 ...
blog.naver.com
8단계. 결과분석 및 해석
ConfusionMatrix로 분류성능을 확인합니다
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
from sklearn.metrics import f1_score, confusion_matrix, precision_recall_curve, roc_curve
def get_clf_eval(y_test=None, pred=None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test,pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, pred)
print('오차 행렬')
print(confusion)
print('정확도 :{0: .4f}, 정밀도: {1: .4f}, 재현율: {2: .4f}, F1 : {3: .4f}, \
AUC: {4: .4f}'.format(accuracy, precision, recall, f1, roc_auc))
get_clf_eval(y_test, dt_prediction)
<omg's comment>
1. 심화 공부가 필요한 부분
히트맵 코드 / 산점도 코드 / 의사결정나무 시각화 코드 / random state 이해하기
2. 추가로 구현해보고 싶은 부분
ROC, AUC 그래프 그려보기 / 연구실 데이터로 의사결정나무 연습해보기
3. 좋은 데이터로 심화 공부 가능하게 해준 중소벤처기업부, KAIST 감사합니다ㅎㅎㅎㅋㅋㅋㅋ
출처: 중소벤처기업부, Korea AI Manufacturing Platform(KAMP), 살균기 AI데이터셋, KAIST(임픽스, 한양대학교 산학협력단, 아큐라소프트), 2020.12.14
'데이터 분석' 카테고리의 다른 글
| [의사결정나무] 개념 (0) | 2021.02.22 |
|---|---|
| [로지스틱 회귀분석] 개념 (0) | 2021.02.22 |
| [K-최근접이웃/KNN] 교반구동장치 AI 데이터셋 (2) 실습/코드 (0) | 2021.01.10 |
| [K-최근접이웃/KNN] 교반구동장치 AI 데이터셋 (1) (0) | 2021.01.09 |
| [의사결정나무/Decision Tree] 살균기 AI 데이터셋 (1) (0) | 2021.01.05 |


