중소벤처기업부가 2020년 12월 14일에 인공지능 중소벤처 제조플랫폼인 'AI 제조 플랫폼(KAMP) 서비스 포털'을 열었습니다.
이 포털에는 중소 제조업체들이 주로 활용하는 핵심 장비 12종에 대한 인공지능 학습용 데이터와 분석 모델이 담겨있습니다.
12개 학습용 데이터 및 분석모델에 대한 가이드북을 제공하고 있어 누구나 수비게 분석을 따라할 수 있습니다.
가이드북을 통해 스마트 공장의 개념부터 인공지능, 데이터 활용까지 공부할 수 있습니다.
지난 포스팅에 이어, 이번에는 교반구동장치 AI 데이터셋으로 KNN 알고리즘을 사용한 분석을 요약하겠습니다~!
데이터 다운로드 및 가이드북은 링크를 참고하세요~!
인공지능 중소벤처 제조 플랫폼
3축(x,y,z) 진동데이터 기반 설비 예지보전을 위한 교반구동장치 데이터 공유 --> 제조AI데이터셋 가이드북
kamp-ai.kr
1. 분석을 시작하기 전에
1-1. 분석 배경
ㅇ 용해공정: 분말 원재료를 정제수 등에 녹이는 작업. 전처리 공정의 첫 번째 단계
ㅇ 본 가이드 북의 용해공정
- 용해탱크의 교반구동장치는 분말 원재료를 액상 원재료에 녹이는 과정에서 원료를 섞어 더 잘 용해되게 함
- 교반구동장치 구조: 모터, 감속장치, 회전축, 교반용 날개 등
- 용해탱크는 사용시간 및 빈도가 높아 고장관리 및 수명관리가 중요함
1-2. 문제 상황
ㅇ 원료 용해액을 후공정 단계에서 다시 분말화하기 때문에 모든 원료가 균일하게 혼합되는 것이 중요
ㅇ 용해탱크는 사용빈도가 높아 고장에 취약함
ㅇ 특히 모터 베어링에 주로 고장 발생
ㅇ 첫 이상징후를 보일 때 대처하는 것이 좋으나 이를 알기 어려움
1-3. 문제 해결
ㅇ 교반구동장치의 모터 베어링에 이상이 있을 때 발생하는 진동데이터와 정상작동 시에 발생하는 진동데이터의 패턴분석을 통해 이상징후를 예측하여 설비 수명관리 및 부품 교체관리에 이용함!
2. 분석 시사점
2-1. 주관적 판단에 의존한 설비관리가 아닌 데이터의 패턴을 AI기법으로 적용해 결함 및 고장 징후 검출
3. 분석 실습
3-1. 제조데이터 소개
-> 가이드 북을 참고하시면 자세한 설명을 확인할 수 있습니다!
3-2. 분석모델 - K 최근접 이웃 회귀 (KNN Regression)
KNN 회귀로 모터 베어링의 이상징후 예측이 가능한 표준데이터를 추출할 수 있음
시간의 흐름에 따라 유연하게 적용 가능하도록 추출
KNN 회귀는 사전에 표준데이터를 추출해놓는 원리!
→ 표준데이터를 통해 예측선을 최종적으로 도출하고, 예측선에 어긋나는 패턴이 검출되는 횟수와 예측이 얼마나 정확히 이루어졌는지를 확인함!
(1) KNN 분류

예를 들어 (1) 주황색 집단: 오렌지, (2) 파란색 집단: 포도, (3) 초록색 집단: 사과로 정의할 때, 종류를 알 수 없는 과일(빨간색)이 새롭게 주어졌을 때 이 과일이 어떤 종류인지 분류하기 위해 KNN 분류가 사용됨.
이런 상황에서 '새로운 과일은 어떤 과일의 특성에 가장 가까울까?'라는 직관적인 질문을 하게 되고,
이는 2차원 그래프 상에서 새로운 데이터가 '거리상 가장 가까운' 데이터와 유사한 집단에 속할 것이라고 예상해볼 수 있다.
새로운 데이터와 기존 데이터들의 거리 계산을 위해 특정 '거리 계산식'을 이용한다.
(2) K의 크기를 어떻게 설정할 것인가? - 과적합 방지의 문제

집단이 가깝게 맞닿아 있는 부분으로 인해 경계를 정확히 정의하기 어려운 경우에는,
K가 1일 때 가장 가까운 데이터로 새로운 데이터를 분류하는 것은 사실 분류 정확도가 낮은 경우가 많다.
경계가 뚜렷하지 않은 특징을 정확한 분류에 대한 '일정한 잡음(noise)'라고 간주하고, 노이즈를 고려한 파라미터를 설정해야 한다.

위의 그림에서 k=1로 설정할 경우, 새로운 데이터는 기존의 데이터와 거리로 봤을 때 파란색 데이터가 가장 가까운 것이 맞지만, 집단을 기준으로 봤을 때 그 데이터는 집단내 잡음일 가능성이 있다.
즉, 새로운 데이터가 파란색 데이터에 가까운 위치에 있더라도 초록색 데이터에 속할 수 있다는 것이다.
따라서 k=1로 설정했을 때 분류가 정확히 된 것인지 의문이 생길 수 있다.
k를 2 이상으로 설정한다면 데이터 집단 간 경계의 모호성 문제를 해결할 수 있고 '모델 과적합'을 방지할 수 있다.
k=3 또는 k=5로 설정하면, 새로운 데이터(빨간색)이 초록색 데이터로 분류되는 것을 확인할 수 있다.
(3) KNN 회귀
KNN 회귀는 가까운 이웃 데이터들을 고려하지만, '개별값을 예측'한다는 차이가 있다.
K개의 이웃 데이터를 이용해 '회귀선'을 도출할 수 있다.
선형회귀와 다른 점은, 하나의 회귀식을 도출하는 것이 아니라, '주어진 입력을 바탕으로 가장 잘 예측된 평균값들의 집합'을 나타낸다는 것.
→ 종속변수에 대한 독립변수의 영향력을 의미하는 회귀계수가 확인되지는 않음으로 주의할 것!
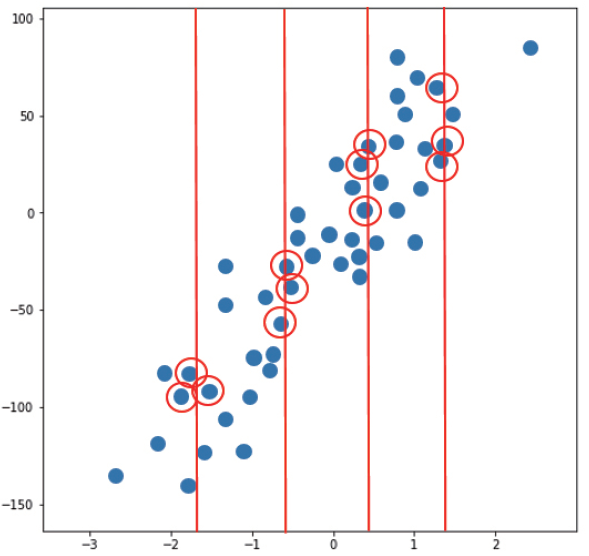
Y값을 예측하기 위해 해당 지점에서 수직선과 가장 가까운 k개의 데이터 값을 확인하고 이를 평균내어 시점 당 하나의 예측값을 출력한다.
예를 들어 X축이 '시간'이라면 모든 시점의 평균 데이터를 예측하게 됨.

모든 시점에서 예측된 값들을 하나의 선으로 연결하면 예측에 사용된 데이터들에 대한 표준데이터를 표시할 수 있음
(4) KNN 회귀의 하이퍼파라미터
하이퍼파라미터란 !?
→ 알고리즘을 활용할 때 분석가가 반드시 설정해야하는 항목
KNN 회귀에서는 (1) K(최근접 이웃 수) 와 (2) 거리함수(데이터 간의 거리 계산식)을 반드시 하이퍼파라미터로 설정해주어야 한다.
보통 k는 훈련 데이터 개수의 제곱근으로 설정하지만, 데이터에 따라 항상 다르며 하나의 클러스터링 안에 클래스 수가 그대로 나오는 경우르 피하기 위해 홀수를 사용하기도 한다.
가장 많이 사용되는 방법은 학습용 데이터와 테스트 데이터를 분리한 뒤 다양한 K값에 대해 제일 작은 예측 오차율이 산출되는 k를 선택하는 것
거리함수는 유클리디안 거리를 많이 사용함.
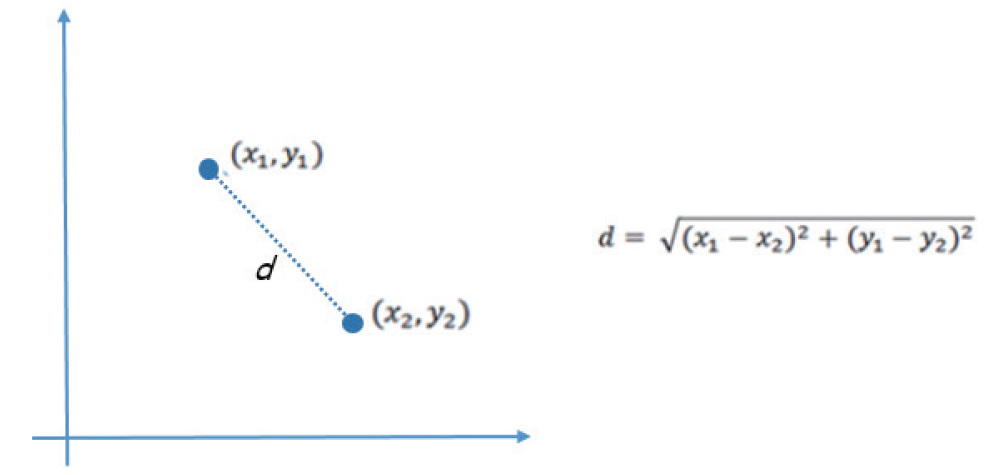
(5) KNN 성능평가 방법
표준데이터를 이용해 검출된 불량 여부와 실제 불량 여부의 일치성을 확인하기 위한 분류 성능 평가 척도로 Confusion Matrix를 이용함.
이는 지난 번 의사결정나무 포스팅의 성능평가 방법과 동일합니다!
[의사결정나무/Decision Tree] 살균기 AI 데이터셋 (1)
중소벤처기업부가 2020년 12월 14일에 인공지능 중소벤처 제조플랫폼인 ‘AI 제조 플랫폼(KAMP) 서비스 포털’을 열었습니다. 이 포털에는 중소 제조업체들이 주로 활용하는 핵심 장비 12종에 대한
data-analysis-expertise.tistory.com
<omg's comment>
용해공정에서 머신러닝 분석의 필요성과 K 최근접 이웃 분류/회귀 이론적 배경을 요약했습니다.
K 최근접 회귀에서 표준데이터를 도출해낼 수 있다는 점을 새롭게 배웠습니다.
다음 포스팅에서 실습을 진행하고 나면 제가 가진 데이터로 KNN을 적용해보는 아이디어가 생겨날 것 같아 기분이 좋네요!
다음 포스팅에서 분석 실습을 진행하겠습니다!
출처: 중소벤처기업부, Korea AI Manufacturing Platform(KAMP), 교반구동장치 AI데이터셋, KAIST(임픽스, 한양대학교 산학협력단, 아큐라소프트), 2020.12.14
'데이터 분석' 카테고리의 다른 글
| [의사결정나무] 개념 (0) | 2021.02.22 |
|---|---|
| [로지스틱 회귀분석] 개념 (0) | 2021.02.22 |
| [K-최근접이웃/KNN] 교반구동장치 AI 데이터셋 (2) 실습/코드 (0) | 2021.01.10 |
| [의사결정나무/Decision Tree] 살균기 AI 데이터셋 (2) 실습/코드 (0) | 2021.01.05 |
| [의사결정나무/Decision Tree] 살균기 AI 데이터셋 (1) (0) | 2021.01.05 |


